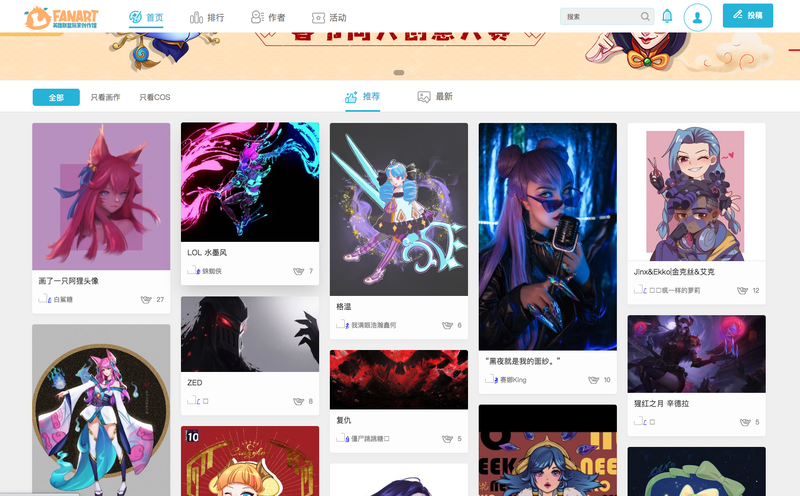
因为图片列表是瀑布流加载,而且是动态渲染,所以使用了selenium模拟浏览器返回加载完成后的数据。
实现原理:中间件定义触底加载更多,直到没有更多后,获取加载完成后的数据,解析得到列表页的全部详情页链接,进入详情页解析正文里的图片,全部保存到管道里自定义保存到本地。
注意:Chromedrive驱动的安装这里就不再说了,参考另一个文章 https://pic.itmresources.com/archives/122799
保存路径:pipelines.py定义好保存的路径
启动:scrapy crawal trpic
爬取中:
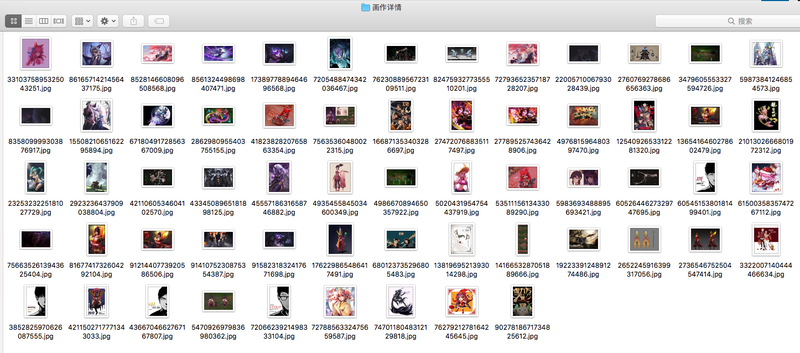
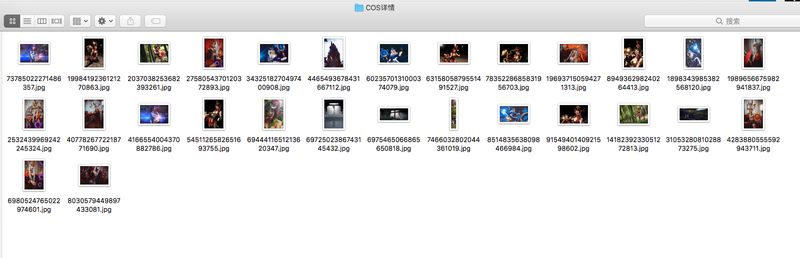
爬取的图片

Demo: