
这是我之前学习scrapy框架时,随便练习使用selenium爬取动态加载的内容的时候,写的练习Demo,爬取的是英雄联盟峡谷之巅的段位排行榜 ,有兴趣的朋友可以学习了解一下。
selenium:这个包可以模拟浏览器访问,然后把js或者ajax加载的内容渲染完成之后,再返回给python做解析,有有兴趣的可以看下官方文档。
数据表结构:
CREATE TABLE `test_db`.`rank` (
`id` INT(11) NOT NULL AUTO_INCREMENT ,
`rank` INT(11) NOT NULL COMMENT '排行' ,
`cover` VARCHAR(255) NOT NULL COMMENT '头像' ,
`name` VARCHAR(255) NOT NULL COMMENT '召唤师名称' ,
`rank_level` VARCHAR(100) NOT NULL COMMENT '段位等级' ,
`rank_source` INT(11) NOT NULL COMMENT '胜点' ,
`win_num` VARCHAR(50) NOT NULL COMMENT '胜' ,
`loser_num` VARCHAR(50) NOT NULL COMMENT '负' ,
`win_rate` VARCHAR(50) NOT NULL COMMENT '胜率' ,
PRIMARY KEY (`id`)
) ENGINE = MyISAM COMMENT = '峡谷之巅排行';运行前请先修改ranking.py里的Chromedriver.exe的路径,根目录下有,如果和你电脑谷歌版本对不上,请重新安装。(安装教程)
运行前先在pipelines.py管道文件里配置好数据库连接配置。
控制台输入命令开始爬取:scrapy crawl ranking
如果运行出现:ModuleNotFoundError: No module named '包名',这个错误很简单,缺什么包装什么包就行了,不过有的包名不一样,pycharm开发工具里面搜包名,_要替换成-才搜索的到。
安装python包:
# 升级pip工具
python3 -m pip install -U pip
# 安装python包
pip install 包名
# 查看包列表
pip list 或 python -m pip list如果安装慢,或者安装超时,将pip源更换到国内镜像
阿里云 http://mirrors.aliyun.com/pypi/simple/
豆瓣 http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学 http://pypi.hustunique.com/
临时使用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
永久修改,一劳永逸:
(a)Linux下,修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件。文件夹要加“.”,表示是隐藏文件夹)
内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
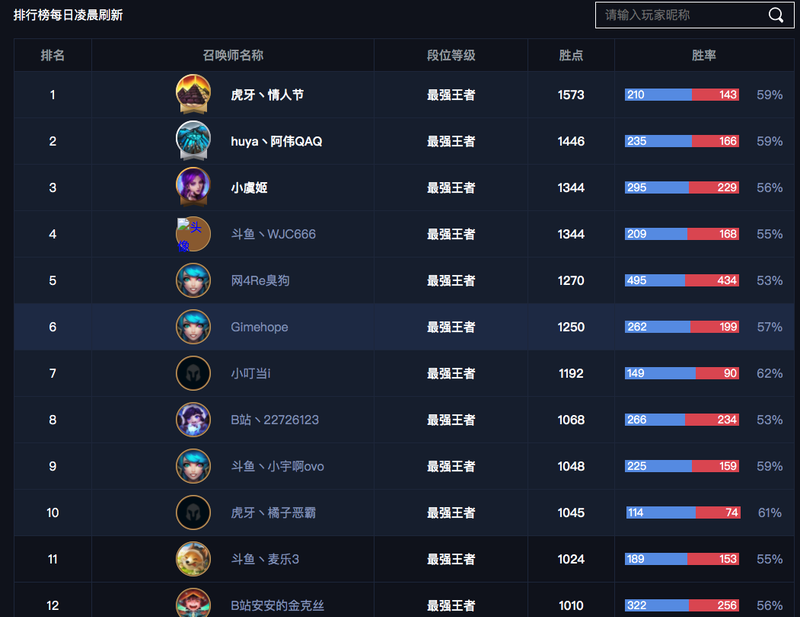
当前网页排行:
爬虫运行中:

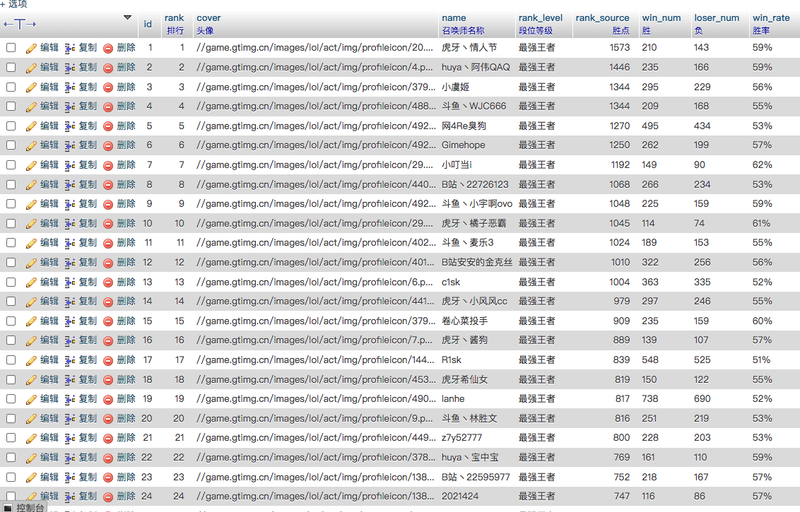
运行后数据库里:
让我们来搜一下C皇当前排名。
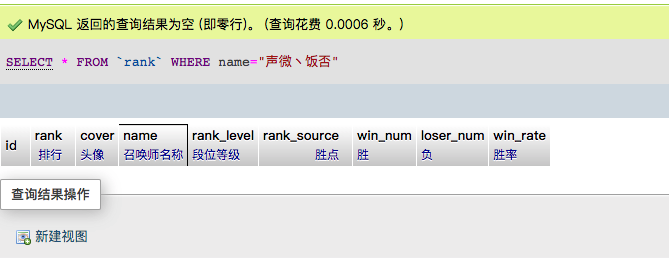
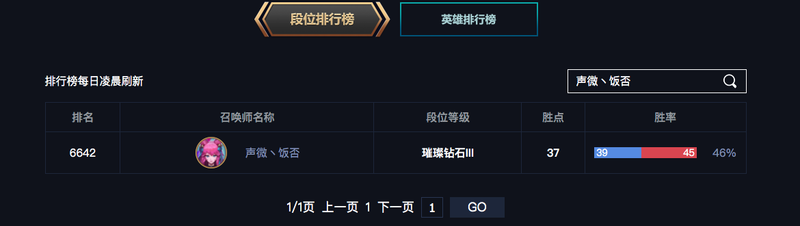
啊哦,看来还没有爬到C皇那一页。
Demo下载: